
The Cross Entropy Loss in PyTorch is used to compute the probability (or loss) of the model performing correctly given a single sample. This loss value is then used to determine how well the model has trained using a classification problem. NN Cross Entropy Loss is a popular training loss for Machine Learning as it is used to train neural networks for classification problems with high performance.
Purpose of using Cross Entropy Loss function
The purpose of using cross entropy loss is to measure the difference between the predicted probabilities outputted by a neural network and the actual probabilities of the target variable in a classification problem. It is a popular loss function used in machine learning, particularly in deep learning, because it is suitable for models with multiple classes and can effectively penalize the model for incorrect predictions.
Cross entropy loss aims to minimize the difference between the predicted probabilities and the actual probabilities by adjusting the model parameters during training. The lower the cross entropy loss value, the better the model is performing on the given classification task. Therefore, the ultimate goal is to minimize the cross entropy loss during training to improve the accuracy of the model.
Cross entropy loss
Using the function CrossEntropyLoss(), we compute the cross entropy loss between the input and target values (predicted and actual). Therefore, It is achieved by the torch.nn module, to determine the cross entropy loss.
Cross entropy loss is designed for classification problems. However, Multiclass classification problems can be trained very effectively using CrossEntropyLoss().
In the following example, there will be a calculation of the cross-entropy of the dummy variables. The loss is calculated between 0-1. Where
0 refers to a perfect model close to actual variables and our goal is to achieve the model close to 0.
from torch import nn
out = nn.CrossEntropyLoss()
# Describe the input variable
input = torch.ones(5)
#print input
print("Input = \n",input)
input = torch.tensor([[0, 1,2, 3]],dtype=torch.float)
print("Input long actual = \n",input)
y = torch.tensor([3], dtype=torch.long)
print("Input predicted = \n",y)
crosseloss=out(input, y)
print('Cross Entropy Loss: \n', crosseloss)Input =
tensor([1., 1., 1., 1., 1.])
Input long actual =
tensor([[0., 1., 2., 3.]])
Input predicted =
tensor([3])
Cross Entropy Loss:
tensor(0.4402)Cross entropy loss PyTorch backward
Here a demonstration about cross-entropy loss PyTorch backward in Python.
- Cross entropy loss backward is used to determine the best fit model between actual and targeted variables.
- Softmax is not a loss but a function. It provides a probability of each element.
- However, backward() function just computes gradient.
- So softmax() function computes with backward() function to determine the gradient.
- Next, compute gradients based on the output backward function. However, You can improve loss in the next training iteration.
#target with class probabilities
import torch
import torch.nn as nn
# Describe the input variable
input = torch.ones(3,requires_grad=True)
print("Input = ",input)
pred = torch.randn(3) .softmax(dim=0)
print('predicted size \n:', pred.size())
lss = nn.CrossEntropyLoss()
out = lss(input, pred)
out.backward()
print("Input:",input)
print("predicted:",pred)
print("Cross Entropy Loss:",out)
print('Input grads: ', input.grad)Input = tensor([1., 1., 1.], requires_grad=True)
predicted size
: torch.Size([3])
Input: tensor([1., 1., 1.], requires_grad=True)
predicted: tensor([0.6004, 0.3339, 0.0657])
Cross Entropy Loss: tensor(1.0986, grad_fn=<DivBackward1>)
Input grads: tensor([-0.2670, -0.0006, 0.2676])Use backward() function without softmax() function
loss = nn.CrossEntropyLoss()
import torch
import torch.nn as nn
# Describe the input variable
input = torch.ones(3,requires_grad=True)
y = torch.empty(3)
out = loss(input, y)
out.backward()
print("Input: \n",input)
print("predicted: \n",y)
print("Cross Entropy Loss: \n",out)
print('Input grads: \n', input.grad)Input:
tensor([1., 1., 1.], requires_grad=True)
predicted:
tensor([0.0000e+00, 1.8980e+01, 7.7549e-14])
Cross Entropy Loss:
tensor(20.8519, grad_fn=<DivBackward1>)
Input grads:
tensor([ 6.3267, -12.6535, 6.3267])Logits with binary Cross entropy loss
The following example demonstrates cross-entropy loss PyTorch logits in Python.
- In cross-entropy loss, PyTorch logits are the net input of the last neuron layer (unnormalized raw value). However, we can also say that logits have an inverse reaction with logistic sigmoid function.
- Define a dummy input and test target the cross entropy loss pytorch function.
- Consider importing BCEWithLogitsLoss(pos_weight=pos_wgt) supported function from torch.nn module. However, Call the function with positive weight.
- Define the above command as variable and pass the dummy inputs and target as argument.
- In PyTorch, there are nn.BCELoss and nn.BCEWithLogitsLoss. However, PyTorch can take raw unnormalized logits for the first and normalized sigmoid probabilities for the second.
- Binary cross entropy refers to the classes of 2.
import torch
# 2 classes, batch size = 3
input = torch.ones([2,3], dtype=torch.float32)
#A prediction (logit)
pred = torch.full([2, 3], 1.0)
#All weights are equal to 1
pos_wgt = torch.ones([3])
c = torch.nn.BCEWithLogitsLoss(pos_weight=pos_wgt)
print("Input: \n",input)
print("predicted: \n",pred)
print("Cross Entropy Loss: \n",pos_wgt)
# -log(sigmoid(1.0))
x=c(pred, input)
xInput:
tensor([[1., 1., 1.],
[1., 1., 1.]])
predicted:
tensor([[1., 1., 1.],
[1., 1., 1.]])
Cross Entropy Loss:
tensor([1., 1., 1.])
tensor(0.3133)Cross entropy loss PyTorch weight
The below example illustrates the cross-entropy loss weight in PyTorch.Cross-entropy loss weight is determined with CrossEntropyLoss(weight=target) by using the torch.nn module. Hence, Invoke the function with a weight parameter.
from torch import nn
import torch
softmax=nn.Softmax()
target=torch.tensor([1.3,2.0])
# weight assign manually to each class.
CrossEntropyLoss = nn.CrossEntropyLoss(weight=target)
#inputvariable
input_var = torch.tensor([[1.3, 2.0],[1.3,2.0]])
#targetvariable
target_var = torch.tensor([1,1])#classes=1, batch size=2
out = CrossEntropyLoss(input_var, target_var)
print(out)tensor(0.4032)Cross-entropy loss implemented on classification model
A Cost Function presents the discrepancy between predicted and expected values. However, In classification models, cost function or cross-entropy, is a measure of how well they predict probability values between 0 and 1.
The Classification Model with low cross-entropy losses was successful to determine a good decision boundary for provided weights and biases.
#import libraries
import numpy as np
import matplotlib.pyplot as plt
#define a function
def func_sigmoid(score):
return 1/(1+ np.exp(-score))
#define another function with def keyword
def error(line_parameter, points, y ):
m= points.shape[0]
p = func_sigmoid(points * line_parameter)
#Cross-entropy loss formula implementation
cross_entropy = -(1/m)*(np.log(p).T * y + np.log(1-p).T * (1-y))
return cross_entropy
#sample points
sample_points = 3
#provide a starting point
np.random.seed(0)
bias = np.ones(sample_points)
#
t_regression = np.array([np.random.normal(5, 2, sample_points),np.random.normal(5, 2, sample_points),bias]).T
b_regression = np.array([np.random.normal(3, 2, sample_points),np.random.normal(3, 2, sample_points),bias]).T
#verically row wise sequence array
allsamplepoints = np.vstack((t_regression,b_regression))
#weight and bias
w1 = -0.3
w2 = -0.35
#Low bias will best fit the target.
b = 2.5
line= np.matrix([w1,w2,b]).T
print ('line_parameter : \n', line)
print ('all_points : \n', allsamplepoints)
#print linear regression
linear = allsamplepoints*line
print ('linear combination : \n', linear)
positive_likelihood = func_sigmoid(linear)
#gives probability of each point being in positive region
print("probabilities",positive_likelihood)
#reshape array of size 3 into shape (6,1)
y= np.array([np.zeros(sample_points),np.ones(sample_points)]).reshape(sample_points*2, 1)
#print Cross Entropy Loss
print('Cross Entropy Loss:',(error(line,allsamplepoints,y)))
# code for plot the Cross Entropy Loss
_,axis = plt.subplots(figsize=(4, 4))
axis.scatter(t_regression[:, 0], t_regression[:, 1],c='gray')
axis.scatter(b_regression[:, 0], b_regression[:, 1], c='r')
plt.draw()
#display 2 D graph
plt.show()line_parameter :
[[-0.3 ]
[-0.35]
[ 2.5 ]]
all_points :
[[8.52810469 9.4817864 1. ]
[5.80031442 8.73511598 1. ]
[6.95747597 3.04544424 1. ]
[4.90017684 3.821197 1. ]
[2.69728558 3.28808714 1. ]
[2.7935623 5.90854701 1. ]]
linear combination :
[[-3.37705665]
[-2.29738492]
[-0.65314827]
[-0.307472 ]
[ 0.53998383]
[-0.40606014]]
probabilities [[0.03302025]
[0.09133977]
[0.34228043]
[0.42373191]
[0.63180866]
[0.3998572 ]]
Cross Entropy Loss: [[0.46380153]]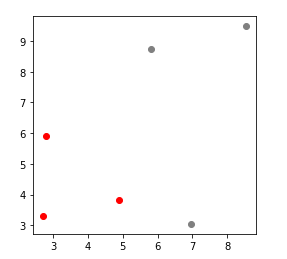
Conclusion
This article demonstrates how the CrossEntropyLoss function used for classification is implemented in PyTorch, including its usage with softmax, weights, and the backward() function. The following topics are covered:
- The purpose of using the Cross Entropy Loss function
- The Cross Entropy Loss function itself
- Implementing the Cross Entropy Loss function with PyTorch’s backward() function
- Logits with binary Cross Entropy Loss
- Using weights with the Cross Entropy Loss function in PyTorch
- Implementation of Cross-Entropy Loss on a classification model.