
Thousands of terabytes of data are generated every day. This data has been stored in different formats depending on the application. Using this data, we are building tens of thousands of machine learning and deep learning models every day to solve real-world problems. XML format is also a data formatting way in which the data is stored. This tutorial is about How to read an XML File in Python. But first, let’s have a brief introduction about what is XML.
Understanding XML: An Overview
XML stands for Extensible Markup Language. As the name implies, it is a markup language that uses tags to indicate what data is inside a document. The goal of developing XML format was to store and transport data without relying on software and hardware tools. It is both human and machine-readable. Reading an XML file is also referred to as parsing the XML file. Parsing means reading the data from the XML file and analyzing it. With Python, you can parse the information and get nice attributes and tags with all elements.
If you want to learn more about Python programming, visit Python Programming Tutorials.
Read data from XML files using the Minimal Document Object Model (DOM)
The mini DOM module of Python provides a parse() function which is used to read the XML file. First of all, you need to install and import XML library into your Python environment. Then use the parse() function to parse the data from this file.
from xml.dom import minidom
# Parse an XML file
file = minidom.parse('./data.xml')
# Display the name of the first tag or child
print(file.firstChild.tagName)catalogNow, we want to know the book IDs. For this, we will use getElementsByTagName() method. It takes the tag name as an input and then by using getAttribute() method we can get the information of that specific attribute. For example, We want to know all the book IDs. So, in this case, the tag is ‘book’ and the attribute is ‘id’.
#use getElementsByTagName() to get tag
models = file.getElementsByTagName('book')
#get ids of all books
for field in models:
id=field.getAttribute('id')
print(id)bk101
bk102
bk103
bk104
bk105
bk106
bk107
bk108
bk109
bk110
bk111
bk112Instead of getting the data one by one using tags, You can also print the whole data in the XML file. Pass the parsed file to toprettyxml() method. It prints out the pretty version of data which means that the data is now readable.
prettyxml = file.toprettyxml()
print(prettyxml)<?xml version="1.0" ?>
<catalog>
<book id="bk101">
<author>Gambardella, Matthew</author>
<title>XML Developer's Guide</title
<genre>Computer</genre>
<price>44.95</price>
<publish_date>2000-10-01</publish_date>
<description>An in-depth look at creating applications with XML.</description>
</book>
<book id="bk102">
<author>Ralls, Kim</author>
<title>Midnight Rain</title>
<genre>Fantasy</genre>
<price>5.95</price>
<publish_date>2000-12-16</publish_date>
<description>A former architect battles corporate zombies, an evil sorceress, and her own childhood to become queen of the world.</description>
</book>
<book id="bk103">
<author>Corets, Eva</author>
<title>Maeve Ascendant</title>
<genre>Fantasy</genre>
<price>5.95</price>
<publish_date>2000-11-17</publish_date>
<description>After the collapse of a nanotechnology society in England, the young survivors lay the foundation for a new society.</description>
</book>
<book id="bk104">
<author>Corets, Eva</author>
<title>Oberon's Legacy</title>
<genre>Fantasy</genre>
<price>5.95</price>
<publish_date>2001-03-10</publish_date>
<description>In post-apocalypse England, the mysterious agent known only as Oberon helps to create a new life for the inhabitants of London. Sequel to Maeve Ascendant.</description>
</book>
<book id="bk105">
<author>Corets, Eva</author>
<title>The Sundered Grail</title>
<genre>Fantasy</genre>
<price>5.95</price>
<publish_date>2001-09-10</publish_date>
<description>The two daughters of Maeve, half-sisters, battle one another for control of England. Sequel to Oberon's Legacy.</description>
</book>
<book id="bk106">
<author>Randall, Cynthia</author>
<title>Lover Birds</title>
<genre>Romance</genre>
<price>4.95</price>
<publish_date>2000-09-02</publish_date>
<description>When Carla meets Paul at an ornithology conference, tempers fly as feathers get ruffled. </description>
</book>
<book id="bk107">
<author>Thurman, Paula</author>
<title>Splish Splash</title>
<genre>Romance</genre>
<price>4.95</price>
<publish_date>2000-11-02</publish_date>
<description>A deep sea diver finds true love twenty thousand leagues beneath the sea </description>
</book>
<book id="bk108">
<author>Knorr, Stefan</author>
<title>Creepy Crawlies</title>
<genre>Horror</genre>
<price>4.95</price>
<publish_date>2000-12-06</publish_date>
<description>An anthology of horror stories about roaches, centipedes, scorpions and other insects </description>
</book>
<book id="bk109">
<author>Kress, Peter</author>
<title>Paradox Lost</title>
<genre>Science Fiction</genre>
<price>6.95</price>
<publish_date>2000-11-02</publish_date>
<description>After an inadvertant trip through a Heisenberg Uncertainty Device, James Salway discovers the problems of being quantum.</description>
</book>
<book id="bk110">
<author>O'Brien, Tim</author>
<title>Microsoft .NET: The Programming Bible</title>
<genre>Computer</genre>
<price>36.95</price>
<publish_date>2000-12-09</publish_date>
<description>Microsoft's .NET initiative is explored in detail in this deep programmer's reference.</description>
</book>
<book id="bk111">
<author>O'Brien, Tim</author>
<title>MSXML3: A Comprehensive Guide</title>
<genre>Computer</genre>
<price>36.95</price>
<publish_date>2000-12-01</publish_date>
<description>The Microsoft MSXML3 parser is covered in detail, with attention to XML DOM interfaces, XSLT processing, SAX and more.</description>
</book>
<book id="bk112">
<author>Galos, Mike</author>
<title>Visual Studio 7: A Comprehensive Guide</title>
<genre>Computer</genre>
<price>49.95</price>
<publish_date>2001-04-16</publish_date>
<description>Microsoft Visual Studio 7 is explored in depth, looking at how Visual Basic, Visual C++, C#, and ASP+ are integrated into a comprehensive development environment.</description>
</book>
</catalog>Parsing XML File using Element Tree Library
To read an XML file in Python, you can use the library module lxml and beautifulsoup bs4.
BeautifulSoup4 supports actual and rite HTML files, and the lxml library supports your reading and writing the XML document. You can install them in your Python environment path by executing this command in your OS(operating system) cmd prompt.
Libraries to install before reading an XML file in Python

First, print the XML document in Python.
Printing the pretty print XML file in Python is possible using the Element Tree parse function.
import xml.etree.ElementTree as ET
k = ET.parse(r"D:\DATA_SCIENCE\python\employee.xml")
l = k.getroot()
m = ET.tostring(l, encoding="unicode")
print(m)
Using Etree To Read An XML File In Python
There are many different ways to read an XML file in Python, but the easiest way is to use the xml.etree.ElementTree class.
The execution process goes in the following steps:
- Import the ElementTree module:
- Provide the path to the XML file:
- Get the top-level element (root), which contains all information about other elements in the XML document
- Print the top-level tag or element:
- Access specific attributes of the first tag
- Access the text contained within subtags of the first tag:
The source code to read the XML file in Python is as follows:
All element has text and attributes in XML. In our case, the top-level element is <root> here and have child elements. The child element text is “monoj.” A text from the XML document contains the first child element of the top-level element, the root.
# importing etree as ET
import xml.etree.ElementTree as ET
tree = ET.parse(r"D:\DATA_SCIENCE\python\employee.xml")
root = tree.getroot()
print(root)
print(root[0].attrib)
print(root[0][1].text)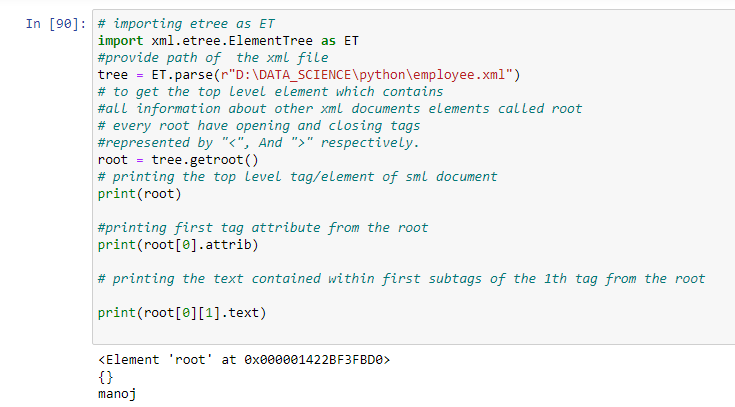
beautifulsoup bs4 to read an XML file in python
BeautifulSoup() will read the document and return a Tree object. A Tree object is a wrapper around a node-set object that contains information about each element/node in the document. The tree object will have a root node or element (which represents the top-level element), and then each element within the document will be defined as its node-set objects inside the tree object.
First, import the BeautifulSoup from bs4.
from bs4 import BeautifulSoupThen, we’ll create a function called BeautifulSoup(open()) as ‘xml’ that takes in an XML string and returns an object of all the elements found in the file.
Read the XML file to a variable under the name xml_read. However, reading the XML data inside the beautifulsoup parser stores the returned object.
xml_read = BeautifulSoup(open(r"D:\DATA_SCIENCE\python\employee.xml"), 'xml')The print() function will display all instances of tag “row” within the current tag.
# Finding all instances of tag `row`
tag_row = xml_read.find_all('row')
print(tag_row )Finding the first instance of a tag and printing its attributes using find()
# Using find() to extract attributes of the first instance of the tag
tag_name = tag_row.find('child', {'name':'monoj'})
print(tag_name)The output will be as follows:

Conclusion
On this page, there is a discussion on how to read an XML file in Python using the BeautifulSoup4 method and ElementTree method. Reading an XML file is not challenging, but you need to install the necessary libraries into your Python terminal. If you want to learn more about Python Programming, visit Python Programming Tutorials.